Bibliographical data and quotations from articles and book’s chapters have been collected within the framework of the RESEE project, in order to fulfil the main objective of establishing Europeanization research on Southeast Europe as a complex historically grounded process; and the specific objectives of: (O1) synthesizing and integrating primary research on Balkans – Southeast Europe since the beginning of the 20th century (even earlier) through clustering and visual mapping of the intellectual historiography, the conceptual content and dynamics of Balkan – Southeast European studies in order to identify the most prominent works, the active research themes and the emerging trajectories in the field; (O2) revisiting the historical usage of the term Europeanization over time and trying to comprehensibly describe the phenomenon it defined, how it has related to other social science concepts and what it historical usage can inform us in today’s context and in the case of the Balkans – Southeast Europe.
The RESEE project has collected, processed and analysed the following kinds of research data:
- A bibliographical dataset of scholarly publications on the Balkan – Southeast European studies generated by combining multiple database sources (Web of Science, Scopus, Jstor, Portico), using explicit search criteria, careful processing and merging techniques, and well-established analytical tools. Link
- A collection of various quotations and their respective bibliographic references of the historical usage of the term Europeanization used in scholarly publications before 1990. Constellate
In addition to collecting the primary dataset, we employed bibliographic and content analysis and used various software (Histcite, VOSviewer, Sci2 Tool, CRExplorer, LancsBox) to process, analyse and visualise the data. Tables, graphs and publications have been produced. Visualisations of the bibliographical data are presented here either in standard graphic (e.g., .png) or interactive (.html or json) formats.
Among the different methods and techniques performed in the research mapping process, we employ here:
- Direct citation analysis, using the HistCite software to map the research historiography of the most prominent publications chronologically and show how research builds on each other. Direct citation analysis builds on the basic assumption that the bibliographic information (cited references) contained in a collection of scholarly publications is sufficient for capturing the historiographic structure of the field (Garfield et al. 2006, 391). HistCite software uses algorithmic historiography to generate a year-by-year citation-based historiography of the bibliographical database collection, identifying the core (most cited) works and visualising direct citation linkages between them (see Garfield 2004; Garfield et al. 2006).
- Co-word analysis, using the VOSviewer software to identify a conceptual map of the major thematic topics based on the relational ties and similarities between the most recurrent terms. The co-word analysis makes use of the terms in the relevant sections of the dataset (e.g. titles, abstracts, keywords) and creates maps of the co-occurrence of specific terms as a measure of similarity (see Morris and Van Der Veer Martens 2008, 229 with further references on the scholar’s criticisms and responses to the use of this method). The VOSviewer software includes text mining functions for creating co-occurrence networks of related words with high relevance, grouped together into clusters to signal recurring thematic topics (see Van Eck and Waltman 2011); and
- Temporal analysis, using Sci2 Tool to explore the variations and map the temporal sequence of emerging and fading research themes over time. The temporal analysis focuses on the evolution of the research field across different periods of time with the aim of identifying patterns, trends, seasonality, or outliers (Cobo et al. 2011, 1385). Burst detection, is a particular temporal analysis, that can be performed using the Science of Science (Sci2) Tool. Sci2 uses Kleinberg’s (2002) burst detection algorithm to determine the unusual increase or decrease rate in the usage frequency of words over time (see Sci2 Team 2009).
- Timeline of scientific publications in Balkan – Southeast European Studies and the local citation scores (1854–2021).

Note: The annual distribution of publications (bars) and the yearly local citation scores within our dataset (continuous line) as % of the total.
- A Historiographic mapping of some of the most prominent publications in Balkan – Southeast European studies (1854–2021)

Note: The vertical axis represents time and the horizontal axis shows the citation network. Each publication receiving more than 35 local citations is presented here by a node (the size of the nodes represents the number of local citation score) with its respective bibliographic data (the author, the year and the title of publication). In the brackets, we report the local citation score. The lines connecting them indicate a direct citation. Please note that for reasons of visual clarity, the map here lists chronologically and links only a few of the most cited publications within our database, unfortunately leaving many other prominent publications visually unaccented.
- Map of Thematic Clusters in Balkan – Southeast European studies (1854–2021)
Labelling and List of Words for the Core Eleven Thematic Clusters
| Label | Cluster number & colour |
| Historic Developments | 1 – Red |
| Economic Growth & European Integration | 2 – Green |
| Balkanism Discourse | 3 – Blue |
| Balkan route: Migrant & Refugee | 4 – Yellow |
| Balkanization & Balkan War | 5 – Purple |
| War | 6 – Turquoise |
| Security | 7 – Orange |
| Country Case Studies | 8 – Brown |
| Central, Eastern and South Eastern Europe | 9 – Rose |
| Europeanization | 10 – Cherry |
| Gender | 11 – Light Green |
Note: The labelling of the thematic clusters was done after the most prominent words (indicated by a higher weight of occurrence) or/and the multitude of all semantically related words in the specific cluster.
- Temporal Bar Graph for Frequent Burst Words in the Titles of the Balkan – Southeast European studies (1853–2021)

Note: The graph presents the burst-words in the titles of our dataset, their intensity of usage (weight) and duration of remaining dominant (length). The area of the horizontal bars proportionally represents how many articles paid attention to those words in the title (the weight is expressed by the thickness of each line) and for how long (the length of each line is expressed in years).
- Historical Usage of Europeanization
- Process-collocates of Europeanization (1867–1990)
Corpus: The corpus used is a small purpose-built sample of sentences using the term Europeanization (or Europeanisation) in the articles (1867–1990). Overall, 2547 articles (2828 sentences) were extracted from Constellate platform (JSTOR and PORTICO). Analysed with LancsBox. Expectedly, the most immediate collocate word is ‘process’. Processes more collocated with Europeanization are modernization and westernization.
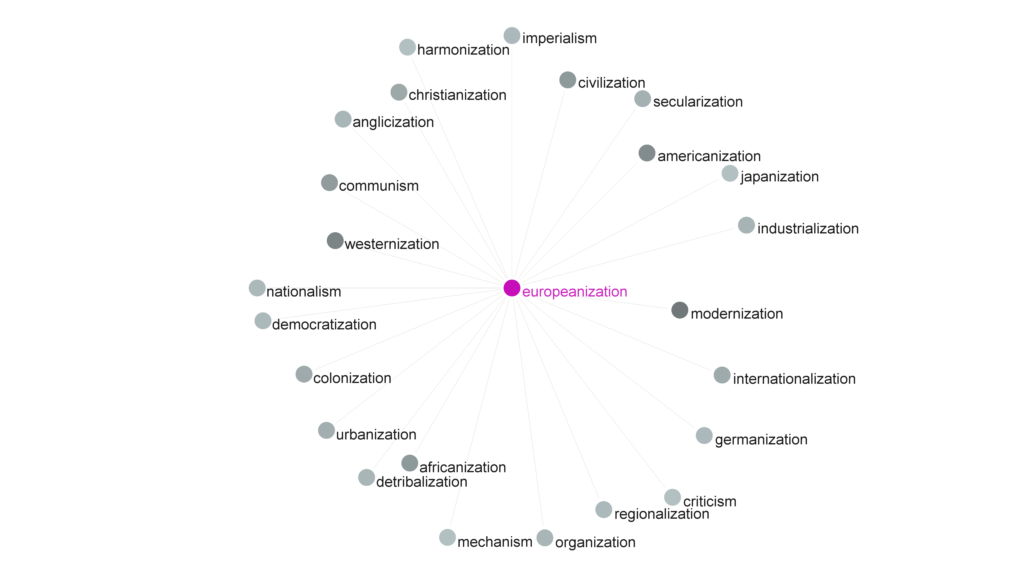
Note: | Search Term: europeanization| Statistic: 05 – MI3| Span: 10-10| Collocation freq. threshold: 5.0| Statistic value threshold: 9.0| CPN: 05 – MI3 (9.0)/ L10-R10/ C: 5.0-NC: 5.0|